I’m not actually sure. I will take a look!
I experimented with updating of the proxyToRaw and rawToProxy and I figured out that it won’t work 100%, because of some code that is in collections.js .For example on this line: https://github.com/frontity/frontity/blob/dev/packages/connect/src/builtIns/collections.js#L12 we would need to pass the context and path to rawToProxy , but there is no way to access those parameters inside of findObservable() . Similarly, for proxyToRaw calls inside of instrumentation , e.g. here: https://github.com/frontity/frontity/blob/dev/packages/connect/src/builtIns/collections.js#L38.The silver lining is that this should only break the built-in objects (Map, WeakMap) and I think that we can work around it eventually.
You’re right, we are moving from a 1-to-1 relation to a 1-to-many.
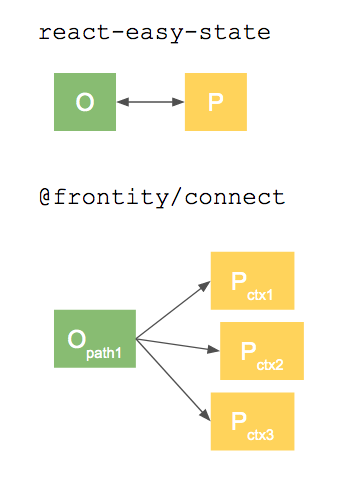
As far as I can remember, react-easy-state only needs the O->P relation to reuse the same proxy for the same object. But that’s not something we need, we will reuse the same proxy using the path+context. But yeah, we’re going to break some stuff of react-easy-state.
By the way, if we need to access state , context , path or root from outside of the proxy, we can use symbols:
proxy[STATE]
proxy[CONTEXT]
proxy[PATH]
proxy[ROOT]
we can also use that approach to attach the path to the real state because path is invariant:
state[PATH]
We’re working on the first PR: https://github.com/frontity/frontity/pull/208 to add state, path and context to the proxies.
The “stable proxy references” implementation involves having to store a “fake target” instead of the real one, because we need to be able to change the reference, without creating a new proxy:
const proxify = (target, context) => {
const fakeTarget = { realTarget: target, context };
return new Proxy(fakeTarget, handlers);
};
It works ok, but all the traps must be used to change this “fake target” for the real one:
handler(fakeTarget, key, ...) {
const target = fakeTarget.realTarget; // extract the real target.
}
It’s not as clean as we thought and it feels kind of hacky because many internal things in JS expect the target to be the real target, obviously. Besides that, the console.log are a bit confusing because people have to look for the real state inside this fake target.
So we’ve been working on a new idea: stable state references (instead of stable proxy references).
It works by adding a new deepOverwrite function that preserves the state references, overwriting the old object with the new one.
Imagine this object with this object references.
const state = {
user (ref1): {
name (ref2): {
first: "Jon",
last: "Snow"
},
city: "Winterfell"
}
}
And an action that overwrites the references like this:
const myAction = ({ state }) => {
state.user (ref3) = {
name (ref4): {
first: "Jon",
last: "Targaryen"
}
}
}
Usually, the result will be:
state = {
user (ref3): {
name (ref4): {
first: "Jon",
last: "Targaryen"
}
}
}
And this patch will be:
{
path: "state.user",
type: "set",
value: (ref3) {
name (ref4): {
first: "Jon",
last: "Targaryen"
}
}
}
If instead of changing the ref1 -> ref3, we do a deepOverwrite in the set handler, the result would be:
state = {
user (ref1): {
name (ref2): {
first: "Jon",
last: "Targaryen"
}
}
}
And the patches would be:
{
path: "state.user.city",
type: "delete"
}
{
path: "state.user.surname",
type: "Targaryen"
}
The implementation of this deepOverwrite function would be something like this:
function deepOverwrite(a, b) {
// Delete the props of a that are not in b.
Object.keys(a).forEach(key => {
if (typeof b[key] === "undefined") delete a[key];
});
Object.keys(b).forEach(key => {
// If that key doesn't exist on a or it is a primitive, we overwrite it.
if (typeof a[key] === "undefined" || isPrimitive(b[key])) a[key] = b[key];
// If it's an object, we deepOverwrite it.
else deepOverwrite(a[key], b[key]);
});
}
This approach has some additional benefits that I really like:
- We can keep using the solid implementation of
react-easy-state. - The patches would be atomic and deterministic out of the box.
- The re-rendering problem would solved out of the box.
But it may have a performance impact when deep-overwriting big objects.
I’ve done a quick test to measure the performance impact: https://codesandbox.io/s/deep-overwrite-hq9r4
The test fetches 10 posts (using _embed to get also categories, authors, media…) from https://test.frontity.io/wp-json/wp/v2/posts?_embed=true. Then it normalizes the result with normalizr and deep-clones it before doing the deepOverwrite.
The JSON is 219Kb (unzipped) so it’s a big object. It takes 20-40 ms to do the deepOverwrite in my computer with a slowdown of x6. That means we would be skipping 2-3 frames for such a big object in a slow device.
I’ve also measured the normalization we are already doing to that big object (done with the normalizr library) and it’s pretty similar:
normalize: 21.870849609375ms
deepOverwrite: 26.866943359375ms
So it doesn’t seem to be that bad. At least won’t be introducing something which is 10x slower to what we already do.
I also think that mobx-state-tree has to do something like this under the hood. I’d try to do another test with this approach vs mobx-state-tree to see if we are still in the same order of magnitude. I’d bet this is still way faster.
Additional considerations about performance:
- It has no impact the fist time you add an object to the state, it only has impact if you overwrite
- It has an opt-in optimization for the final user when needed: don’t overwrite objects, just mutate the primitives!
- The
deepOverwritewould be performed before any React change is triggered, so it won’t affect the render or any subsequent animations triggered by that mutation.
For example, we are currently overwriting all the entities fetched with actions.source.fetch(...), but there’s no reason to do that. So we can check if that entity exists before overwriting it. We can make it opt-in in the future when we add { force: true } in case it’s a real refresh. So even the “slow” deepOverwrite of my test can be pretty much avoided.
Another interesting idea worth exploring is to make mutations asynchronous, instead of synchronous. If we do that, the deepOverwrite function is a great candidate for the new facebook’s scheduler function (used internally for React Concurrent). That would solve all the performance problems because deepOverwrite could be chunked and there won’t be any missing frame.
The problem with making mutations asynchronous is that a filter won’t be ready synchronously:
// This "filter" adds an @ before the user name. "Jon" -> "@Jon".
const myFilter = {
test: ({ path }) => path === "state.user.name",
onMutation: ctx => {
ctx.value = "@" + ctx.value
}
}
// If mutations are synchronous:
const myAction = ({ state }) => {
state.user.name = "Jon"; // This triggers myFilter
console.log(state.user.name) // -> "@Jon"
}
// If mutations are asynchronous:
const myAction = ({ state }) => {
state.user.name = "Jon"; // This triggers myFilter
console.log(state.user.name) // -> "Jon"
}
But maybe we can find a solution for that.
I was experimenting with a different approach:
Maybe we could create a wrapper for a built-in Proxy, which could dynamically change the targets inside of the proxy without breaking the references. A sketch of this approach is mentioned here.
It seems like a kinda complicated idea and I was not able to use use the snippet from StackOverflow nor do I understand it completely  I’m tempted to say that for this reason alone we should probably abandon this idea… I’d ideally like our code to be understandable to an average developer like me
I’m tempted to say that for this reason alone we should probably abandon this idea… I’d ideally like our code to be understandable to an average developer like me 
Now, I investigated the deep-overwrite idea a little more and I realized that we have to change how we handle the reactions. Basically, if a user reassigns the state like in the example:
const myAction = ({ state }) => {
state.user (ref3) = {
name (ref4): {
first: "Jon",
last: "Targaryen"
}
}
}
then we have to “follow” the change down to the actual leaves of the state tree in order to have the patch like:
{
path: "state.user.city",
type: "delete"
}
{
path: "state.user.surname",
type: "Targaryen"
}
Agree. Besides, having proxies inside proxies will obfuscate the debugging even further:
Yes, but, if I’m not mistaken, we only have to change “how we queue” reactions. The rest is going to work out of the box.
This is our current set handler (I omitted some comments and irrelevant code):
function set(target, key, value, receiver) {
const hadKey = target.hasOwnProperty(key);
const oldValue = target[key];
const result = Reflect.set(target, key, value, receiver);
if (!hadKey) {
// Queue a reaction if it's a new property.
queueReactionsForOperation({ target, key, value, receiver, type: "add" });
} else if (value !== oldValue) {
// Queue a reaction if there's a new value.
queueReactionsForOperation({ target, key, value, oldValue, receiver, type: "set" });
}
return result;
}
This is a rough example of how the new set handler would look like:
function set(target, key, newValue, receiver) {
const hadKey = target.hasOwnProperty(key);
const oldValue = target[key];
const result = Reflect.set(target, key, value, receiver);
// If both the old value and the new value are objects, deepOverwrite.
if (isObject(oldValue) && isObject(newValue) {
deepOverwrite(oldValue, newValue);
// Queue a reaction if it's a new property.
} else if (!hadKey) {
queueReactionsForOperation({ target, key, value, receiver, type: "add" });
// Queue a reaction if there's a new value.
} else if (value !== oldValue) {
queueReactionsForOperation({ target, key, value, oldValue, receiver, type: "set" });
}
return result;
}
function deepOverwrite(a, b) {
// Delete the props of a that are not in b.
Object.keys(a).forEach(key => {
if (typeof b[key] === "undefined") {
// Trigger a delete reaction.
queueReactionsForOperation({ target: a, key, oldValue: a[key], type: "delete" });
// Delete the key.
delete a[key];
}
});
Object.keys(b).forEach(key => {
// If that key doesn't exist, we add it.
if (typeof a[key] === "undefined") {
queueReactionsForOperation({ target: a, key, type: "add" });
a[key] = b[key];
// If that key exist, it's a primitive and the value has changed, we overwrite it.
} else if (isPrimitive(b[key]) && a[key] !== b[key]) {
queueReactionsForOperation({ target: a, key, oldValue: a[key] type: "set" });
a[key] = b[key];
// If it's an object, we deepOverwrite it again.
} else {
deepOverwrite(a[key], b[key]);
}
});
}
The work of this implementation is being done in this PR: https://github.com/frontity/frontity/pull/213
There’s a failing test in wp-source because of we’ve changed how we invalidate observers.
For example, if an observer is subscribed to two props:
const state = {
prop1: "1",
prop2: "1",
observe(() => {
const { prop1, prop2 } = state.obj;
console.log(`prop1: ${prop1} & prop2: ${prop2)`);
});
And you change the state.obj all at once:
state.obj = { prop1: "2", prop2: "2" };
You’ll get only one call to the observer:
// console.log => prop1: 2 & prop2: 2
Because there was only one mutation: state.obj.
But with this implementation we have two mutations: state.obj.prop1 and state.obj.prop2 and we get two console.logs:
console.log => prop1: 2 & prop2: 1 // Unstable?
console.log => prop1: 2 & prop2: 2
This is not something that couldn’t exist in the past, because if you do this:
state.obj.prop1 = "2";
state.obj.prop2 = "2";
you’ll get the two console logs as well.
console.log => prop1: 2 & prop2: 1 // Unstable?
console.log => prop1: 2 & prop2: 2
Going forward, we need to decide a few things:
- Are we going to have a common internal implementation for middleware and computations?
- Are we going to have a common external API for middleware and computations?
- Are middleware/computations going to be sync/async by default?
This is a computation:
observe(() => {
console.log(state.user.name);
});
Although they can have other forms, like connect or Mobx reactions:
// React connect computation
const UserName = ({ state }) => (
<div>{state.user.name}</div>
);
export default connect(UserName);
// Mobx reaction computation
reaction(
() => state.user.name,
name => console.log(state.user.name);
});
Middleware needs to run before the event happens because it needs to be able to modify it:
- Before the mutation is done.
- It can abort the mutation.
- It can modify the mutation.
- Before the action is executed.
- It can abort the action execution.
- It can modify the arguments.
Once the action has been executed or the mutation has been done, middleware and computations are basically the same thing. For example:
// This...
observe(() => {
console.log(state.user.name);
});
// ...is equivalent to this:
addMutationMiddleware(({ state, next }) => {
await next() // wait until the state mutation has finished.
console.log(state.user.name);
});
// or this...
addMiddleware({
test: ({ path }) => path === "state.user.name",
afterMutation: ({ state }) => {
console.log(state.user.name);
}
});
Sync or Async?
Async problems:
- Actions won’t work if they use a value right after changing it:
// This middleware aborts a mutation.
addMiddleware({
test: ({ state }) => state.user.name,
onMutation: ({ abort }) => {
abort();
}
});
const state = { user: { name: "Jon" } };
const myAction = ({ state }) => {
state.user.name = "Daenerys"; // Doesn't trigger the middleware just yet!
console.log(state.user.name) // -> "Daenerys" -- WRONG VALUE!!
}
Async benefits:
- We can improve the performance using facebook’s scheduler.
- We can avoid “unstable” states by batching mutations together:
addMiddleware({
test: ({ state }) => {
state.user.name;
state.user.surname;
},
afterMutation: ({ state }) => {
console.log(state.user.name + " " + state.user.surname);
}
});
const state = { user: { name: "Jon", surname: "Snow" } };
const myAction = ({ state }) => {
state.user.name = "Daenerys";
state.user.surname = "Taergaryen";
// If synchronous, this would trigger two console.logs:
// 1. "Daenerys Snow" -- WRONG!! (unstable)
// 2. "Daenerys Taergaryen" -- Right
}
State dependencies
Apart from middleware for action executions and state mutations, we need another middleware for “state dependencies”.
That will be used by our devtools to show “who is listening to what”. For example:
- UserName component is listening to state.user.name.
We do that with the context we pass to that component. For example, this is the context of the state object we pass to UserName:
const context = {
type: "component",
name: "UserName",
id: 123,
};
We could add that ability to our middleware:
addMiddleware({
name: "user name log",
test: ({ state }) => state.user.name,
reaction: ({ state }) => console.log(state.user.name),
});
And the dependency reported would be:
- "user name log" middleware is listening to state.user.name.
I guess there’s not much point on adding that to computations/middleware if they don’t have a name:
observe(({ state }) => {
console.log(state.user.name);
});
- ??? middleware is listening to state.user.name.
By the way, when I write I use a lot of possible “middleware APIs” just to get a feeling of how they look like… Please bear with me 
About the async problem with actions that use the value right after chaning it, like this:
// This middleware aborts a mutation.
addMiddleware({
test: ({ state }) => state.user.name,
onMutation: ({ abort }) => {
abort();
}
});
const state = { user: { name: "Jon" } };
const myAction = ({ state }) => {
state.user.name = "Daenerys"; // Doesn't trigger the middleware just yet!
console.log(state.user.name) // -> "Daenerys" -- WRONG VALUE!!
}
We could solve it with an opt-in await:
const myAction = async ({ state, mutationsFinished }) => {
state.user.name = "Daenerys"; // Doesn't trigger the middleware just yet!
await mutationsFinished(); // Now we trigger them.
console.log(state.user.name) // -> "Jon" <-- Right value
}
Or we could do the opposite, make them sync by default and add a function to batch them and make them async. Something similar to Mobx transactions:
// This just works:
const myAction = async ({ state, transaction }) => {
state.user.name = "Daenerys";
console.log(state.user.name) // -> "Jon" <-- Right value
}
// But you can batch changes and improve performance on big deep
// overwrites using transaction:
const myAction = async ({ state, transaction }) => {
await transaction(() => {
state.user.name = "Daenerys";
state.user.surname = "Taergaryen";
});
console.log(state.user.name);
}
Neither of those are ideal, but I don’t see another way out so far.
I think there is another problem here actually:
If we allow aborting actions, it’s gonna possibly be problematic: what if a particular action issues several mutations and then the user relies on the fact that the first mutation has happened? EDIT: I realized that you address that later on, Luis, so just keep reading 
I think that making middleware async can result in explosion in complexity. MobX run sync and Michel gives some good reasons for keeping it this way here: https://hackernoon.com/the-fundamental-principles-behind-mobx-7a725f71f3e8 I think you alluded to this before, but after our fiasco with the deepOverwrite I’m willing to be a bit more humble about my own ideas. I asked him on twitter if he has any further thoughts about sync/async.
I wanna point out that I have some reservations about middleware being able to abort actions and call other actions (which will then trigger other middleware). I feel like this is both likely to result in a spiderweb of action -> middleware -> another action called from middleware -> middleware for that action -> and so on…
I think that they are not exactly the same. The observe cannot be async (e.g. react components are pure synchronous functions). So, as far as I understand the concepts and the implementations have to differ… unless I’m missing something
I’m not sure if I see the value in having the middleware to be async at this point. My gut feeling is that: a) the sync implementation is gonna be simpler. b) I feel like transactions are possibly an easier concept to grasp (pretty much all DB systems have transactions). And I’m also guessing that there is probably no third way here - MobX has runInAction for this reason.
In a more general sense, I feel like we should take a little step back and think of the WHY of frontity-connect… and the middleware? Because I have a feeling like I’m trying to solve some very specific technical problems, but maybe we’re missing the forest for the trees (I really like that saying  ) What I mean is that I understand that we want to have a super dev-friendly state manager with devtools for best possible developer experience, but what are the actual problems that we try to solve? Is there a way we can get away with maybe doing much less work and getting 90% of the result (at least for now)? I mean this all in very real sense and not just philosphically.
) What I mean is that I understand that we want to have a super dev-friendly state manager with devtools for best possible developer experience, but what are the actual problems that we try to solve? Is there a way we can get away with maybe doing much less work and getting 90% of the result (at least for now)? I mean this all in very real sense and not just philosphically.
Just as a sort of PS: I also have some vague idea about how we could maybe make our middleware more like an effect system in the spirit of react hooks. Basically, the observers are like wrappers for computations (functions). And react components are just functions which can have effects. So, maybe there is a way to reuse the familiar hooks API to control the execution of those functions. But also maybe this is nonsense. I’m talking about something like (this is completely improvised) :
// state middleware
const userMiddleware = ({state}) => {
// it runs some effect only on state.user change
useEffect(() => {
}, [state.user]);
// if we return null the state update is aborted
return null;
// we can just return unmodified state
return state
// or we can modify the state update
state.user = 'Michal';
return state.user;
};
userMiddleware()
I read that. Good one:
I found the original article on archive.org:
I agree with Michel that sync mutations are indispensable, in order to avoid this problem:
const user = observable({
firstName: “Michel”,
lastName: “Weststrate”,
fullName: computed(function() {
return this.firstName + " " + this.lastName
})
})
user.lastName = “Vaillant”
sendLetterToUser(user) // <- needs an updated "user"
And I agree with Michel that sync reactions are preferable. But I don’t think sync reactions are indispensable.
Actually, it looks like in the version of nx-js/observer-utils of that article observers were always async. In the current version, they are sync with an opt-in async (with the schedule option).
I understand your concern and it’s probably a good one, but I wouldn’t like to add constraints in the beginning. Imagine that one package needs to trigger an action when the action of other package is aborted. If we limit the action execution in middleware, we will limit that type of interactions.
Oh, yeah, sorry. I was talking about how we trigger middleware and reactions, not about the type of callbacks they support.
At this point, I think we need a glossary of terms to be able to communicate better.
I agree with you that simpler is better but there’s no way to mix transparent sync transactions with async/await actions: https://mobx.js.org/best/actions.html
So we need to find a compromise for that.
Nice idea. I’ll add it with the rest so we can explore it.
I agree. Let’s take a step back, do a summary of the current state and the overall goal.
Glossary
-
"Raw state":
The original state object developers declare in their app. -
"State":
The state object after it has been proxified by our library. -
"Actions":
The functions developers declare in their app. -
"Action execution":
One execution of an action. -
"Mutation":
A change in some part of the state. -
"Computation":
Callbacks subscribed to a specific action or part of the state. They are executed after that action is executed or that mutation happens. – We’ve used “reactions” or “observers” to refer to this before this post. -
"React Computation":
React components subscribed to a specific part of the state. They are re-rendered after the mutation happens. – This is our currentconnectfunction. -
"Middleware":
Callbacks subscribed to a specific action or part of the state.
They are executed before that action is executed or that mutation happens. -
"Transaction":
A function or implementation that joins all the mutations that happened during its duration together in order to avoid multiple unnecessary calls to computations.
@mmczaplinski feel free to edit this post to add/modify any concept.
Goals
I think these are still valid:
- Minimum rerender guarantee
- Avoid breaking object/array references on mutations
- Middleware support for action executions
- Middleware support for mutations
I’d add these two more, to be more concise:
- Computations triggered by successful mutations
- Computations triggered by successful action executions
Avoid breaking object/array references on mutations
Just for the record, Michal realized we cannot fix this without breaking other use cases of references.
So in order to solve this:
const state = {
user: {
name: "Jon",
surname: "Snow"
}
};
const asyncAction = async ({ state }) => {
// Store a reference to state.user.
const user = state.user;
// Yield the action, maybe do some fetching...
await new Promise(resolve => setTimeout(resolve, 5000));
// Consider that while this function is waiting, the
// changeNameObject actions is called, changing the
// reference of state.user.
// Now, user.surname is not valid anymore. Still holds
// the value of "Snow".
console.log(user.surname); // <- "Snow"
console.log(user.surname === state.user.surname); // <- false
};
We are breaking this:
const state = [{ id: 0 }, { id: 1 }];
// Use object references to swap an item array
const temp = obs[0];
obs[0] = obs[1];
obs[1] = temp;
So we cannot solve this bug.
The implementations proposed (stable-proxy-references and deep-overwrite) do not apply anymore.
Alternative solution
We can find a way to warn the developer when we detect that a reference is used without accessing the root state after an await:
const user = state.user;
await something();
console.log(user.name); // <= warn about unsafe use.
Minimum rerender guarantee
We have one solid implementation in mind that still applies: the deep-overwrite. Although it has its drawbacks so we can discuss alternatives.
Middleware support for action executions
They need, at least, the ability to:
- Subscribe to specific actions.
- Abort action executions.
- Modify the action arguments.
It’d be great if they can:
- Be removed by other packages.
- Be reprioritized by other packages.
I’ll write later about the different ideas we have so far for the API.
Middleware support for mutations
They need, at least, the ability to:
- Subscribe to specific mutations.
- Abort mutations.
- Modify the mutation.
It’d be great if they can:
- Be removed by other packages.
- Be reprioritized by other packages.
I’ll write later about the different ideas we have so far for the API.
Computations triggered by successful mutations
They need at least the ability to:
- Subscribe to specific mutations.
It’d be great if they can:
- Avoid “unstable” runs (somehow using transactions in our actions).
I’ll write later about the different ideas we have so far for the API.
Computations triggered by successful action executions
They need at least the ability to:
- Subscribe to specific actions.
I’ll write later about the different ideas we have so far for the API.
Implementation ideas for “minimum rerender guarantee”
deep-diff
The deep-overwrite implementation still applies although it wouldn’t overwrite anymore. We can call it deep-diff.
smart-deep-diff
If we were to avoid diffing all the nodes to improve performance, the only thing that I can think of is to diff only the nodes with subscriptions.
So, for example, if there are only nodes with middleware/computations subscriptions are the orange nodes, we only need to deep-diff through the orange lines.
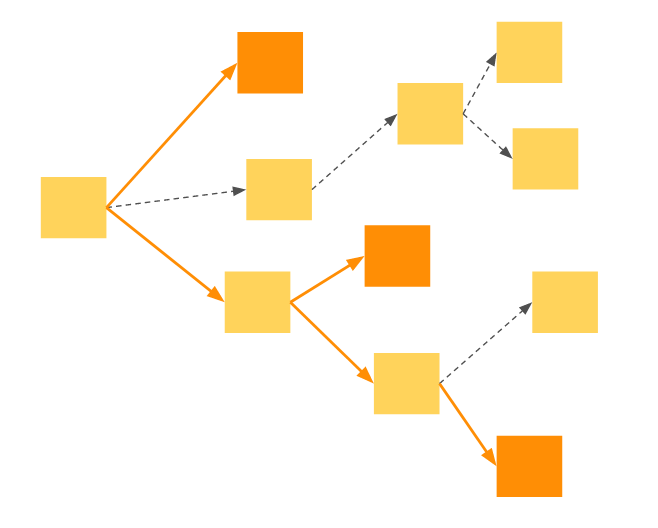
The main disadvantage I see of smart-deep-diff vs deep-diff is that we loose the ability to do subscriptions with string/regexp of paths.
For example, in this scenario:
const state = { user: { name: "Jon", surname: "Snow" } };
addMiddleware({
test: ({ path }) => path === "state.user.name",
...
});
If we trigger this mutation:
state.user = { name: "Jon", surname: "Targaryen" };
How do we know which node ("user.name" or "user.surname") has subscriptions and which not?
Some thoughts/questions:
1. Mutations that overwrite references
For example, should this two mutations be treated differently even tho they end up with the same state?
const state = { user: { name: "Jon" } };
// Mutation 1:
state.user.name = "Ned";
// Mutation 2:
state.user = { name: "Ned" };
Should they trigger this computation? Both? None? Only one?
observer(() => { console.log(state.user); });
I guess the question reduces to: should mutating a node from an object reference to different object reference trigger a mutation for that node?.
This is true for the current implementation but it was false for deep-overwrite.
2. Same reference in multiple parts of the state.
Do we allow to point to the same reference in multiple parts of the state?
const state = { arr: [] };
const obj = { value: 1 };
state.arr[0] = obj;
state.arr[1] = obj;
This would mean a couple of things:
- We cannot have one path per proxy: what’s the path of
obj?state.arr.0orstate.arr.1? - It will behave differently in the server than in the client, due to the serialization of the
stateto be sent to the client (because at that point, the references are broken).
// server:
state.arr[0].value = 2;
state.arr[1].value === 2 // <- true
// Serialize the state to send it to the client...
const seralizedState = JSON.stringify(state);
// Rehydrate state in the client...
const state = JSON.parse(seralizedState);
// client:
state.arr[0].value = 2;
state.arr[1].value === 2 // <- false, still 1 because they have different references
If we don’t want to allow this, should we deep-clone when we detect the same reference being used twice or should we throw an error?
smart-deep-diff
If we were to avoid diffing all the nodes to improve performance, the only thing that I can think of is to diff only the nodes with subscriptions.
So, for example, if there are only nodes with middleware/computations subscriptions are the orange nodes, we only need to
deep-diffthrough the orange lines.
The main disadvantage I see ofsmart-deep-diffvsdeep-diffis that we loose the ability to do subscriptions with string/regexp of paths.
So far the only solution to this based on the discussion with Luis is to “proxify” the middleware. So, we are able to “subscribe” the parts of the state that are used in a particular middleware and only trigger the middleware if those are changed. In essence, treating the middleware as just another kind of computation. What are the drawbacks / caveats with this approach?
1. Mutations that overwrite references
Should they trigger this computation? Both? None? Only one?
observer(() => { console.log(state.user); });I guess the question reduces to: should mutating a node from an object reference to different object reference trigger a mutation for that node? .
This is true for the current implementation but it was false for
deep-overwrite.
I would quite strongly argue that the answer should be both. Even though some of the nodes of the “new” object are the same as in the “old” one, the INTENTION of the developer in this case was: "Overwrite state.user". I think if we try to “help” them by not showing those mutations, we will end up confusing them.
I recall that the redux devtools show this kind of “noop” mutation quite elegantly. The details are slightly different but I think the idea still holds. Basically, they show you the action and the the whole new and old objects. However, they also have a separate view where you can see the “diff” between the new and old states:
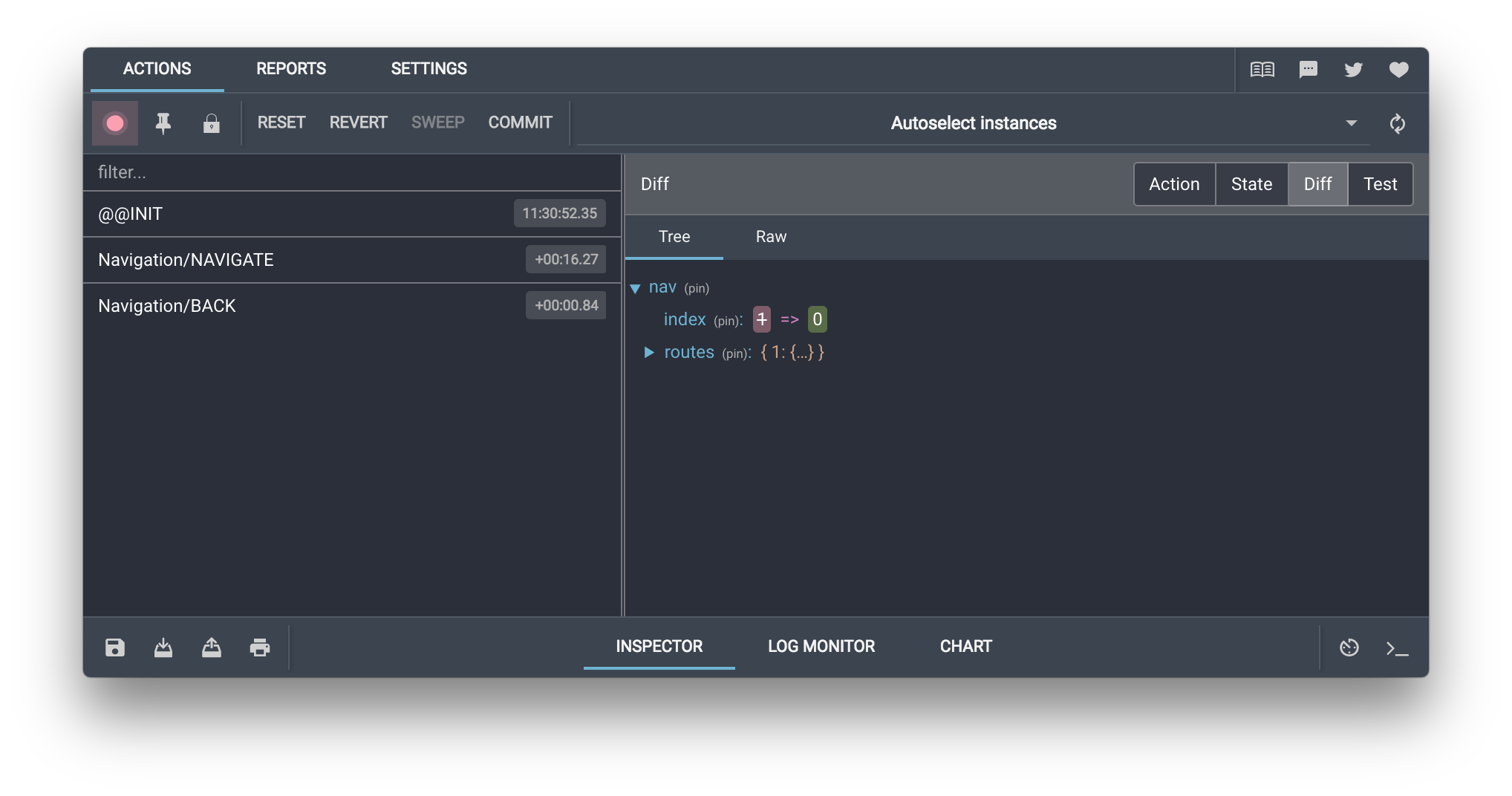
This way, it’s more clear and predictable. If the developer was overwriting state.user, we shouldn’t try to second-guess their intention
So, in the case of this mutation:
const state = { user: { name: "Jon" } };
// Mutation 1:
state.user.name = "Ned";
// Mutation 2:
state.user = { name: "Ned" };
what would happen in Mutation 2. is that the computation is triggered, but we would have an “empty” diff so to speak.
Which actually brings me to an interesting idea that we could capture the mutations that result in an “empty” diff because those are mutations that would result in an unnecessary rerender and possibly warn the user about this !!!
EDIT: As a counterpoint, seems like Mobx-State-Tree for example does not work like this and does not trigger mutations if the references have changed but the actual values are the same.
I really like your idea. Actually, if we do the deep-diff in the devtools and we also track which components are listening to which parts of the state, the devtools would be able to tell the developer about all the unnecessary rerenders that could be optimized.
It’s still not as good as making everything optimized by default but pretty good for our first version 
Ok, this means we can simple work on adding middleware support for the current implementation, right?