1. Context and scope
Frontity Connect is the name of Frontity’s state manager.
It can also be used outside of Frontity (https://codesandbox.io/s/frontityconnect-minimal-example-f7pw5), although that part is not documented yet.
The npm package is @frontity/connect although when used in Frontity you can import connect directly from the main frontity package:
// In a Frontity project:
import { connect } from "frontity";
// In an external project:
import connect from "@frontity/connect";
Our current implementation is a fork of react-easy-state which is based on @nx-js/observer-utils. These two libraries were created by Miklos Bertalan.
On top of that, we implemented a new API for actions and derived state, heavily inspired by overmind.
Both react-easy-state and overmind implement a pattern called transparent reactive programming (TRP). This pattern appeared in the JavaScript world thanks to Meteor’s Tracker library that later served as inspiration for Michel Westrate’s mobx.
The key concept to understand in TRP is that there are two types of entities: observables & computations. When observables are used inside computations, the library adds an internal dependency between then. When that observable is mutated, the library runs again any dependant computation.
In this article, Ryan Carniato gives a great explanation of TRP (although he calls it “Fine-Grained Reactive Programming”). There’s also a good explanation of how the dependency graph works on this old Michel’s article, back from the initial days of Mobx.
Although the three libraries mentioned so far (mobx, react-easy-state and overmind) implement TRP, mobx does it with a combination of ES5 proxies and special objects/arrays, while both react-easy-state and overmind do it with ES6 proxies and plain javascript objects/arrays. @frontity/connect is also based on ES6 proxies.
We chose not to use any of those libraries and instead fork react-easy-state because we have a more complex use case than the regular React apps: in Frontity all the code is contained in packages, some of them made by the developer itself, but many of them created by the community.
Similar to what happens in WordPress, there’s a need for a powerful hook/extensibility system among all these packages. For that reason, we need to add middleware to both action executions and state mutations. These are some of the things packages should be able to do:
- Listen to the actions of other packages (
add_action in WordPress).
- Modify args or even abort other package actions.
- Listen to mutations of the state of other packages (this is normal in TRP).
- Modify or even abort those mutations (
add_filter in WordPress).
Besides that, the state manager API is so critical in the developer experience of Frontity itself that we deemed important to have total control over it. The middleware will also give us other opportunities, like for example releasing powerful devtools, like the ones of overmind.
The overmind inspired API we implemented on top of our react-easy-state fork is:
Actions (without params):
const actions = {
toggleFilter: ({ state }) => { state.filter = !state.filter },
fetchTodos: async ({ state }) => { state.todos = await api.getTodos() }
}
actions.toggleFilter()
actions.fetchTodos()
interface Actions {
toggleFilter: Action<MyPkg>
fetchTodos: Action<MyPkg>
}
Actions (with params):
const actions = {
addTodo: ({ state }) => name => { state.todos.push({ name }) }
fetchTodo: ({ state }) => async id => { state.todos[id] = await api.getTodo(id) }
}
actions.addTodo("finish the state manager")
actions.fetchTodo(374)
interface Actions {
addTodo: Action<MyPkg, string>
fetchTodo: Action<MyPkg, number>
}
Derived State:
const state = {
todos: [],
completedTodos: ({ state }) => state.todos.filter(todo => todo.completed)
}
state.todos
state.completedTodos
interface State {
todos: Todos,
completedTodos: Derived<MyPkg, Todos>
}
Derived State Functions:
const state = {
todos: [],
filteredTodos: ({ state }) => completed =>
state.todos.filter(todo => todo.completed === completed)
}
state.todos
state.filteredTodos(false)
interface State {
todos: Todos,
filteredTodos: Derived<MyPkg, boolean, Todos>
}
React Connect
import connect from "@frontity/connect";
const Toggle = ({ state, actions }) => (
<>
<div>Toggle is {state.active ? "active" : "inactive"}</div>
<button onClick={actions.toggle}>toggle!</button>
</>
);
export default connect(Toggle);
Create Store & Provider (unnecessary in a Frontity project):
import { Provider, createStore } from "@frontity/connect";
const store = createStore({
state: {
active: false,
inverse: ({ state }) => !state.active
},
actions: {
toggle: ({ state }) => {
state.active = !state.active;
}
}
});
const App = () => (
<Provider value={store}>
<Content />
</Provider>
);
We chose react-easy-state over overmind because the code is much simpler to start with.
2. Goals
There are the design goals we set at the beginning of the first implementation.
 : Supported/available
: Supported/available
 : Not ready yet
: Not ready yet
– MobxStateTree is an opinionated version of Mobx.
-
Full Typescript support - Overmind & MobxStateTree
-
Zero boilerplate - Overmind & MobxStateTree
-
Easy to learn - Overmind
-
State as a plain javascript object - Redux & Overmind
-
State mutations (devs don’t have to deal with immutability) - Overmind & MobxStateTree
-
Async actions using async/await - Overmind
-
Serializable snapshots - MobxStateTree & Redux
-
Serializable actions - MobxStateTree & Redux
-
Serializable mutations (patches) - MobxStateTree
-
Minimum rerender guarantee - MobxStateTree
-
Avoid breaking object/array references on mutations - MobxStateTree
-
Deterministic mutation (patches) - MobxStateTree
-
Middleware support for actions - Redux & MobxStateTree
-
Middleware support for mutations - none
-
Filter support - none
-
Devtools for actions and state - Redux & Overmind
-
Devtools for components - Overmind
-
Listen to state mutations - MobxStateTree & Overmind
-
Nested derived state - MobxStateTree
-
Small bundle size - Redux & Overmind
These are the specific goals we want to achieve in this iteration:
-
Minimum rerender guarantee
-
Avoid breaking object/array references on mutations
-
Middleware support for actions
-
Middleware support for mutations
-
Serializable mutations (patches)
Minimum rerender guarantee
In order to provide the best possible developer experience, @frontity/connect should be able to detect when a primitive value of the state hasn’t changed, even in cases when one the object reference containing that value has changed.
For example, these two equivalent actions should behave exactly the same:
actions: {
user: {
changeNameObject: ({ state, actions }) => {
state.user = { name: "Jon", surname: random() };
actions.user.changeNameProperties();
},
changeNameProperties: ({ state }) => {
state.user.name = "Jon";
state.user.surname = random();
}
}
}
state.user.name hasn’t changed (it is still “Jon”), but most state managers today won’t optimize this and will re-render any component which is listening to state.user.name:
Avoid breaking object/array references on mutations
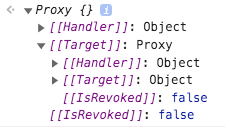
There is a bug that affects all the current ES6 proxy-based libraries when using async actions which is not easy to debug or catch. Consider this state and actions:
state: {
user: {
name: "Jon",
surname: "Snow"
}
},
actions: {
user: {
asyncAction: async ({ state }) => {
// Store a reference to state.user.
const user = state.user;
// Yield the action, maybe do some fetching...
await new Promise(resolve => setTimeout(resolve, 5000));
// Consider that while this function is waiting, the
// changeNameObject actions is called, changing the
// reference of state.user.
// Now, user.surname is not valid anymore. Still holds
// the value of "Snow".
console.log(user.surname); // <- "Snow"
console.log(user.surname === state.user.surname); // <- false
},
changeNameObject: ({ state, actions }) => {
state.user = { name: "Jon", surname: "Targaryen" };
},
}
}
Middleware support for actions
We need to execute callbacks for action executions. Those callbacks:
- Can subscribe to an action, a set of actions or to all actions.
- Start before the action is executed.
- Can await until the action is executed (
await next like Koa, for example).
- If the action is sync, they can await until the action has finished.
- If the action is asyc, they can await both until the action has started and unil the action has finished. Maybe something like (
await started and await finished instead of next)
- It’d be great if we later reuse the API of this “awaiting” for our server middleware.
- Can abort the action execution.
- It can be done with a koa-like prop (
ctx.abort = true) or a function (abort()). The benefits of the koa-like approach are that you don’t need a separate isAborded prop and that a subsequent action could easily “unabort” the execution.
- We need to decide if, after the abortion, the rest of middleware is run or not.
- Get a relevant context of the action. Some examples:
- Action name (“myAction”).
- Action path (“actions.packageName.myAction” or maybe an array instead of string).
- A unique identifier.
- A parent. Maybe called
triggeredBy? It probably needs several properties, like type (“action”, “component”…) and the identifier of the parent or a reference to its context. If we use the reference we need to be very careful with garbage collection to ensure old action execution contexts can be removed by the GC.
- isAsync (we only know this after the action has started the execution looking if it returned a promise).
- Get the arguments of the action and can mutate them at will.
Middleware support for mutations
We need to execute callbacks for action executions. Those callbacks:
- Can subscribe to a mutation, a set of mutations or to all mutations.
- Start before the mutation is done.
- Can await until the mutation is done (
await next() like Koa, for example).
- Get the context of the mutation (similar to the action execution contexts).
- Receive the patch with the information of what is about to happen.
- Maybe receive the new value and the old value (maybe not needed if the
patch and the current state have that info).
- Can mutate the patch or the new value to modify the mutation.
- Can abort the mutation (similar to action execution abortions).
We can use context’s parent or triggeredBy property to implement the protect/unprotect state feature of this types of libraries, and thrown an error or log a warning when people try to modify state outside of an action.
Middleware could easily be able to use the mutation patches to generate immutable snapshots (using immer for example) for things like the devtools.
3. Design Challenges & Implementation Ideas
Avoid breaking object/array references on mutations
I’ve made a proof of concept about how to preserve proxy references to solve this problem.
-> https://codesandbox.io/s/frontity-connect-stable-proxy-references-5knj5
If we use this approach, the things we still need to work on are:
- Ensure proper garbage collection.
- Make it work properly with all
object stuff, like ownKeys.
Attaching contexts to action and state
In order to attach different contexts to actions and components my proposal is to reproxify the state for each action execution or component instance with a proxy that has both the state (or actions) and the context in its target.
I did a more detailed explanation in this video, including the object reference bug and how to solve it:
Instead of a createStore, we have a reproxify that accepts the state (or action) and the context. That reproxification happens inside connect each time a new component instance is created and inside the action executions.
You can create other proxies apart from those, like for example one for the console that you latter add to window.frontity or for the devtools in case we add the possibility of changing the state or dispatching actions from there.
const config = { actions, state, libraries };
const consoleContext = { type: "debug", parent: null... }
window.frontity = reproxify(config, consoleContext);
If we create middleware to protect state mutations outside actions, it can bypass that behavior if the type is "debug" for example.
Minimum rerender guarantee
This is probably the biggest challenge we have now.
We need to decide:
- What type of patches do we emit:
- The ones we get from the action.
- Optimized to be deterministic and minimum.
- How do we diff-by-value to avoid component re-renders or running middleware when values didn’t change.
Adding the middleware callbacks
There are several approaches. The MobxStateTree approach:
addMiddleware(state, myMiddleware);
Maybe a new prop in the package:
export default {
state...
actions...
middleware // or a better name
}
Maybe an array with names and priorities in libraries, like what we are already doing for html2react processors and wp-source handlers.
libraries.middleware.push({
name: "my-middleware",
priority: 10,
subscription: ...
callback: ...
})
The benefit of this approach is that packages can change the priority or even remove the middleware added by other packages.
Subscriptions
1. We need both the action and state middleware to be able to subscribe to any number of actions/state.
We can use an approach similar to reaction in Mobx:
// One action
({ actions }) => actions.pkgName.myAction
// A set of actions
({ actions }) => {
actions.pkgName.myFirstAction;
actions.pkgName.mySecondAction;
}
// All actions?
Or string/regexps:
// One action (string)
"actions.pkgName.myAction"
// A set of actions (or regexp)
"actions\.pkgName\.my(First|Second)Action"
// All actions
"actions"
Same for state.
If we go with the reaction approach, there is one problem:
- How do you listen to all state changes below certain path?
const state = {
user: { name: "Jon", surname: "Snow" }
};
// Subscribe to the state.user object reference or to any change to
// user.name and user.surname?
({ state }) => state.user
One solution would be to iterate through the object keys, but it’s not straightforward and it gets complex if the object has many nested levels:
({ state }) => Object.keys(state.user) // only one level
({ state }) => JSON.stringify(state.user) // all nested levels
If we go with the string/regexp approach, we lose typings.
Maybe we can combine both.
2. Subscriptions can be done with two approaches: a callback or a promise that resolves.
Callback type, this is a bit like takeEvery in Redux Saga or reaction in Mobx:
// Create the middleware
const myMiddleware = {
subscription: ({ actions }) => actions.pkgName.myAction,
callback: ctx => {
// do stuff...
}
}
// Add it to the array
libraries.middleware.push(myMiddleware);
Promise type, this a bit like take in Redux Saga or when in Mobx:
const myMiddlewareAction = async () => {
const ctx = await waitFor(({ actions }) => actions.pkgName.myAction);
// do stuff...
}
If you need to repeat for each action execution, use a while or call the action again:
const myMiddlewareAction = async () => {
while (true) {
const ctx = await waitFor(({ actions }) => actions.pkgName.myAction);
// do stuff...
};
}
Benefits of the promise approach are that you have more control over when the middleware kicks in or stops. Cons of the promise approach are that other packages cannot remove the middleware, because it’s not exposed in a public array.

 . I think that middlewares should run in the order they are defined (like in mobx-state-tree or express). Let’s picture the (action) middleware execution as a stack :
. I think that middlewares should run in the order they are defined (like in mobx-state-tree or express). Let’s picture the (action) middleware execution as a stack :

 We can control the traps (
We can control the traps ( Even if we go with mongoDB-like notation:
Even if we go with mongoDB-like notation: 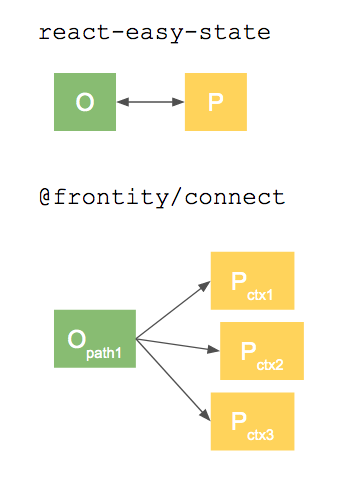
 I’m tempted to say that for this reason alone we should probably abandon this idea… I’d ideally like our code to be understandable to an average developer like me
I’m tempted to say that for this reason alone we should probably abandon this idea… I’d ideally like our code to be understandable to an average developer like me