We are going to change type for taxonomy to match the API.
What about if we allow either a name or an object in the functions that accept a name and a page? Like source.fetch, source.data and router.set?
source.fetch("/category/nature");
source.fetch({ name: "/category/nature", page: 2 });
We also need to decide if we call it name or path.
@David, what do you think?
Uhm, I like it!
About how to call that property, I’m not really sure. We could name it path as it will be the most usual kind of value, but there will be other cases where path won’t fit, e.g. custom lists.
I like the idea of having the exact same API for source.fetch , source.data and router.set, so maybe path is the best option:
actions.source.fetch("/category/nature");
state.source.data("/category/nature");
actions.router.set("/category/nature");
or
actions.source.fetch({ path: "/category/nature", page: 2 });
state.source.data({ path: "/category/nature", page: 2 });
actions.router.set({ path: "/category/nature", page: 2 });
so simple!
1 Like
Ok, you have convinced me 
Ok, we have launched the beta! 
Now it’s time to rethink some aspects of the Source API that need to be fixed, like 404 support for archive pages.
At this moment, when you use source.data(path), that path must be the pathname of the URL without the page (i.e. without /page/2 or similar). That is because pages are stored right now in the same data object, inside the property pages (data object is loosely explained here).
The problem is is404 isn’t set for each page but for the whole data object and this won’t let you know which page is actually a 404.
I’ll post some options I’m working on soon.
We another problem with the links because in the API they include the wordpress domain: https://test.frontity.io/wp-json/wp/v2/posts

When devs use that .link property to populate their links, it shows the wrong url:
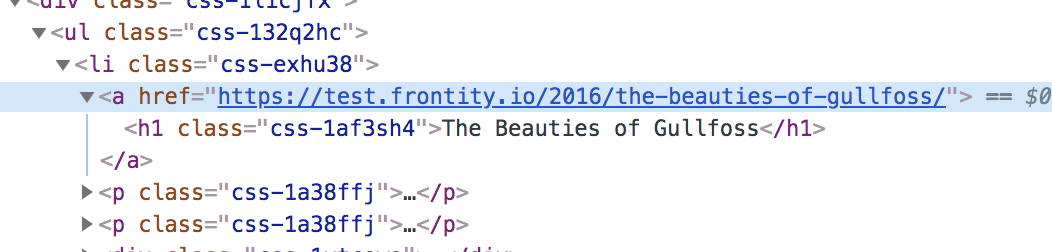
It works because we are ignoring that domain in actions.router.set(), but they should be fixed.
Possible solutions:
- Change the WP domain for the
state.frontity.urldomain. - Remove the domain so they are paths:
/my-link.
I’ve opened a bug:
I see. Uhm, I prefer to transform links into paths as we are using paths more often than links. And also populate function wouldn’t need to check any property outside state.source (this is the object it receives as argument).
About 404's, one thing we could do is to move is404 property inside each page.
Right now, is404 property is being set by fetch action. In order to be consistent, if archive handlers must set this property for not-found pages, then fetch action should not set this property at all, and so, only handlers should be responsible to set this value.
Other option would be to create a data object for each path with pagination (/page/2).
Regarding the 404 problem I think it would be a good approach to have the very same API for all source.get source.fetch and router.set. So yes, I would do as separate data entry for each page.
That’s one of the options I was thinking. 
If we decide to maintain the same API as you mentioned before, the way you access archive pages would be:
const page1 = state.source.get("/category/nature")
const page2 = state.source.get({ path: "/category/nature", page: 2 })
As we are currently using dataMap to store the data objects, we would need to transform the second get call parameters to a string, something like "/category/nature/page/2", in order to create a reference to that page (i.e. source.dataMap["/category/nature/page/2"]).
The structure of the data object would end up like this:
const page1 = {
taxonomy: "category",
id: 7,
isArchive: true,
isTaxonomy: true,
isCategory: true,
items: [{ type, id, link }],
is404: false
}
Ok, some considerations:
-
We need a final specification for the
pathOrObjAPI, used in source.fetch, source.get and router.set. Something like:- You can pass a string with the
pathor an object with apathandpage. - If the
pathhas a domain, it will be stripped out. - If the
pathhas a page, it will be assigned to thepagevariable and it will be stripped out. - If
pathhas a page butpageis present,pagewill prevail. - If page is not present either in
pathorpage, it will be 1.
- You can pass a string with the
With this API, there 3 ways to access page 2:
const page2 = state.source.get("/category/nature/page/2")
const page2 = state.source.get({ path: "/category/nature/page/2" })
const page2 = state.source.get({ path: "/category/nature", page: 2 })
-
The
pathOrObjtopath&pageconverters should live in thesourcepackages as a library. Routers (or other packages) should be agnostic to the final urls. -
I agree with you, the
source.datakeys could be"/category/nature/page/2".isFetchingandisReadystart making sense again, don’t they?
And a question:
- How’s the API to access all fetched pages of a category going to be?
I find passing a full string to the path param a bit confusing. If we can pass "/category/nature/page/2" as a single param, maybe it doesn’t make sense to have the object version of that api.
The problem is that sometimes developers have the full url (for example, from a post.link) and sometimes they have the path and the page (for example, from router.path and router.page).
If we don’t allow both, they have to convert them, which is bothersome. Sometimes is even difficult to know what they have, for example the Link component can receive both full link or path and it doesn’t know which one it get.
Maybe explaining it this way is less confusing:
state.source.get(path)
state.source.get({ path, page })
My suggestion is: You can’t. Access each page separately.
Because even for an infinite scroll you want to have each page in a separate React component:
<Page1 />
<WayPoint /> <!-- Launch actions.router.set ->
<Page2 />
<WayPoint /> <!-- Launch actions.router.set ->
<Page3 />
@David, once you move source.data(...) to source.get(...) you are going to move source.dataMap to source.data, right?
Indeed. There is no reason to maintain dataMap with that name anymore.
I’m going to add this to the issue I’m writing right now.
1 Like